#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <stdio.h>
void winner()
{
printf("that wasn't too bad now, was it? @ %d\n", time(NULL));
}
int main(int argc, char **argv)
{
char *a, *b, *c;
a = malloc(32);
b = malloc(32);
c = malloc(32);
strcpy(a, argv[1]);
strcpy(b, argv[2]);
strcpy(c, argv[3]);
free(c);
free(b);
free(a);
printf("dynamite failed?\n");
}
Intro
This level introduces the Doug Lea Malloc (dlmalloc) and how heap meta data can be modified to change program execution. The goal for this level is to call the winner function.
First, let’s look at the difference in structure of free and allocated memory chunks (ones we allocate with malloc):

Image 1: Representation of chunks in memory [1]
- Prev_size: If previous chunk is allocated, the size field represents data from that chunk.
- Size: Size of free chunk.
- FD pointer: Pointer to next free chunk in doubly linked list.
- BK pointer: Pointer to previous free chunk in doubly linked list.
- Unused space: Space where user data would be stored if allocated.
- Size: Size of chunk, this field is used for easier merging of chunks.
In contrast, the structure of allocated chunks is:
- Previous size: If previous chunk is allocated this field represents last 4 bytes of that chunk. If previous chunk is free, this field represents the size of that chunk.
- Size: Size of this chunk including chunk metadata (header). Last bit of this chunk (called P or “prev_inuse” bit) indicates if the previous chunk is in use or not.
- User data: Space available for user data.
Important thing to note here are the relations between those two chunk types: Imagine you have a user allocated chunk of memory which looks as the left side of Image 1. If we convert this chunk into a free chunk type (right side of Image 1), the first 8 bytes of “User data” will be represented as FD and BK pointers of the free chunk. We will need this later because it is crucial for our exploit.
Let’s see how our level looks like in memory:

Image 2: Level representation in memory
As we can see, the three pointers (a, b and c) are located on the stack and point to their corresponding allocated memory chunks which are located on the heap.
The attack vector we use in this level is the vulnerable strcpy call which doesn’t check how many bytes get written into the buffer and thus allowing us to cause overflows.
Short reminder on how free works: It is important for memory allocator to avoid fragmentation, that is most of your memory is allocated in a large number of non-contiguous blocks. To avoid this, the allocator needs to coalesce/merge contiguous free chunks. I found a very good and short explanation of how free works on Sploitfun blog [2] and source code for dlmalloc at [3]. So merging forward (if next chunk is also free) or backward (if previous chunk is free) works as follows:
Merging backwards:
- Check if previous chunk is free: “Previous chunk is free, if current freed chunk’s PREV_INUSE (P) bit is unset.” [2]
- Merge if free: “unlink (remove) the previous chunk from its binlist, add previous chunk size to current size and change the chunk pointer to point to previous chunk.” [2]
Merging forward:
- Check if previous chunk is free: “Next chunk is free, if next-to-next chunk’s (from currently freed chunk) PREV_INUSE (P) bit is unset. To navigate to next-to-next chunk, add currently freed chunk’s size to its chunk pointer, then add next chunk’s size to next chunk pointer.” [2]
- Merge if free: “unlink (remove) the next chunk from its binlist and add next chunk size to current size.” [2]
We mentioned a “unlink” gets executed. Unlink is used to remove a chunk from doubly linked list of free chunks. This unlink call is very important and looks something like this:

Image 3: Unlink macro
P is the chunk to unlink, BK and FD are variables used for redirection. Look at the right side of Image 1.
- FD = P -> fd: pointer to the next free chunk is stored in FD
- BK = P -> bk: pointer to the previous free chunk is stored in BK
- FD -> bk = BK: we need to change the BK pointer of the free chunk following the chunk we are unlinking to point to the chunk before the one we are currently unlinking.
- BK -> fd = FD: we need to change the FD pointer of the previous free chunk to point to the chunk following the chunk we want to unlink.
After this steps, the chunk pointed to by P will be unlinked from the doubly linked list of free chunks.
Now we can think about the idea of how to pass this level: Using unconstrained strcpy writes we could overflow data from one chunk to overwrite another chunk’s memory, thus allowing us to change its metadata (the allocated chunk’s prev_size and size fields from left part of Image 1). Arbitrary write to the size field allows us to change its prev_inuse bit, effectively changing the status of the previous chunk from allocated to free. By changing a neighboring chunk’s status to free, the free() function that gets called on the other neighboring chunk will trigger the unlink merging routine on the chunk we falsely set to be free. By manipulating the fields in the falsely set free chunk (which is actually allocated), the FD -> bk = BK line from unlink routine will give us an arbitrary memory write because we will control the addresses in FD and BK pointers. The details about this attack will be shown in the next chapter.
Solution
Solution steps:
- Find the address of winner.
- Find the redirection location, that is, a way which will redirect the program execution to the winner function.
- Put the address of winner at the redirection location.
- Test the exploit.
Note that I didn’t pass this level on my first try. My failed attempts are also documented and the errors I made are pointed out and explained.
Step 1: First, load our program in GDB using command: “gdb heap3”, next, set the disassembly output to Intel syntax using command: “set disassembly-flavor intel”. After this is done, we can begin. Get the winner function using command: “print winner” which will give you the address of the winner function. I explained in more detail (with pictures) how to do this in previous levels so I won’t do it again there to not repeat myself. The address of winner is: winner@08048864
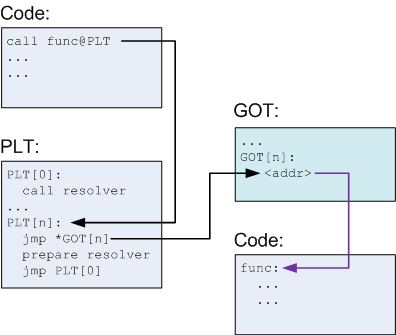
Step 2: From discussions from previous levels, I picked the GOT way of redirecting program execution because it is the most reliable one. If we disassemble main function using “disass main”, by looking at line we can see that the call to printf from 28th line in the given C source gets replaced with puts as an optimization. The puts call is located in a library so it needs to be resolved using Global Offset Table and Procedure Linkage Table, as explained in the previous levels. So we need to find the landing location from the PLT jump. Because PLT is just a bunch of code, we can disassemble it using comand: “disass 0x8048790” which gives us the below output:

Image 4: disassembling PLT
Output from Image 4 shows that the PLT trampoline jumps to the GOT entry located at redir_loc@0x0804b128 in the data section.
Step 3: Ok, now to the nasty part. We want to somehow write the address of winner from Step 1 to the redir_loc redirection location from Step 2. The way to do this is by modifying allocated chunk headers and forcing the unlink method to be called on a chunk we trick the program to think it’s free.
(FAILED ATTEMPT #1) My idea was to overflow the “b” allocated space from Image 2 to overwrite the chunk header metadata (prev_size and size fields) belonging to “c” allocated space and thus, when free gets called at line 24 from our C source, trick the program to think that the previous chunk (the “b” chunk) is free and unlink it, causing the “b” chunk’s first 8 bytes of “User data” field to be interpreted as FD and BK and thus giving us the arbitrary write we need to write the address of winner to redir_loc. Considering the code for backward merging from [2] I designed my exploit:

Image 5: backward merging code snippet
./heap3 AAAA `python -c ‘print “redir_loc_bytes” + “winner_addr_bytes” + (32 – 4 – 4) + chk_b_size_4B + even_size_val ‘` CCCC
- AAAA: dummy bytes for “a”, not used.
- `python -c ‘print “redir_loc_bytes” + “winner_addr_bytes” + (32 – 4 – 4) + chk_b_size_4B + even_size_val ‘`: First print 4 bytes representing the redir_loc, then write 4 bytes representing winner_addr, and then fill the rest of the “b” allocated space. After that write “b” chunk size (which has the value 0x29) and another 4 bytes which will represent size of the “c” allocated space with last bit set to 0 which indicates that the previous chunk is not in use (is freed).
- CCCC: dummy bytes for “c”, not used
I will encode the memory structure of allocated and free chunks as follows (for easier understanding):
(A, chunk_name(a/b/c) | prev_size, size, user_data…) => Allocated chunk
(F, chunk_name(a/b/c) | prev_size, size, FD, BK, unused_space…) => Free chunk
After exploit code gets called, the heap would look something like this (before the first call to free):
(A, a | prev_size, size, “AAAA“)
(F, b | prev_size, size, redir_loc, winner_addr, padding)
(A, c | 0x00000029, even_size_val, “CCCC”)
After first call to free(c), the program would get tricked that the “b” chunk is free because of the overwritten “c” chunk’s size field which will end with a 0 bit which indicates that previous chunk is not in use. After that, free(c) would call unlink on the “b” chunk and thus causing winner_addr to be written at redir_loc (Image 3, line 4). The value 0x00000029 is used for navigating to the start of the previous chunk by Image 5, line 4.
Reason this approach fails: The value 0x00000029 I needed to input via command line couldn’t be given because bash always strips the null bytes (because they represent string terminator or something like that). Second, even if I did input those bytes, line 4 from Image 3 (FD -> bk = BK) would actually write BK at (FD + 12), that will result in writing winner_addr at redir_loc+12.
(FAILED ATTEMPT #2) We failed miserably when trying the previous exploit, so what are the alternatives? It is shown, with a simple trick, that is possible to use negative numbers to make things work. I said previously that bash wouldn’t accept small numbers because they contain NULL bytes which bash would ignore. But what if we input really really large numbers, so large that they are actually interpreted as negative integers?
If we set the “c” chunk’s prev_size to -8 and its size to -4 (which is still even and indicates that the previous chunk is free), we can get the forwards merging unlink call to actually work. Consider the new heap structure (before free(c)) after the follwing shellcode:
./heap3 AAAA `python -c ‘print “B”*32 + 0xfffffff8 + 0xfffffffc ‘` `python -c ‘print “C”*8 + (redir_loc – 12) + winner_addr’`
(A, a | prev_size, size, “AAAA“)
(A, b | prev_size, size, padding)
(A, c | 0xfffffff8, 0xfffffffc, “CCCCCCCC”, (redir_loc – 12), winner_addr)
What will happen here when free(c) gets called is the following: The program will see that the “c” chunk’s size field is set to 0xfffffffc which represents -4 and because it is an even value, it will think the previous chunk is free. Then, by Image 5, line 4, it will navigate to the previous free chunk by subtracting its prev_size field (0xfffffff8 = -8) from the start of “c” chunk pointer and thus actually adding +8 and moving into the “c” chunk by 8 bytes, arriving at the beginning of the memory allocated by malloc(c). We can then forge an “virtual” chunk inside the chunk “c”‘s “User data” field which will be interpreted as a free chunk and unlinked. This looks like this:

Image 6: heap state after executing user exploit
The “CCCCCCCC” bytes represent fake prev_size and size bytes in the fake chunk made inside the “c” chunk “User data” space after which (redir_addr – 12) and winner_addr are located, which represend FD and BK because the fake chunk is considered free.
Reason this approach failed: This approach will actually overwrite redir_addr with winner_addr, but some code after that will try to write at some address inside .txt section which is write protected. Here is a snippet of that problem:

Image 7: writing to protected .txt section
Indeed, by executing GDB command “maintenance info sections” we can see that the address 0x08048864 + 0x8 belongs to .txt section.
(SUCCESSFUL ATTEMPT) Ok, now that I knew that the problem is writing to .txt protected section, and because we have plenty of space allocated on the heap, we could write a simple shellcode which will redirect our execution to the winner function. So instead of providing winner_addr, we will provide shellcode_addr which we will put inside the “a” chunk “User data” space.
There is a neat website that can compile shellcode for us: https://defuse.ca/online-x86-assembler.htm#disassembly
If you don’t want to use the site, you can compile it manually:
- make a file shellcode.asm containing the following instructions:
- mov eax, 0x08048864
- jmp eax
- compile the file using the command: nasm -f elf shellcode.asm
- link the file using the command: ld -m elf_i386 -o shellcode shellcode.o
- using objdump -D shellcode command, extract instruction bytes
Our working payload is now:
./heap3 `python -c ‘print “A”*16 + “\xb8\x64\x88\x04\x08\xff\xe0″‘` `python -c ‘print “A”*32 + “\xf8\xff\xff\xff” + “\xfc\xff\xff\xff”‘` `python -c ‘print “B”*8 + “\x1c\xb1\x04\x08” + “\x18\xc0\x04\x08″‘`
Parameters:
- “A”*16: shift padding
- “\xb8\x64\x88\x04\x08\xff\xe0”: shellcode
- “A”*32: padding for “b” chunk
- “\xf8\xff\xff\xff”: -8
- “\xfc\xff\xff\xff”: -4
- “B”*8: dummy bytes for fake prev_size and size for fake chunk
- “\x1c\xb1\x04\x08”: fake chunk’s FD (redir_loc – 12)
- “\x18\xc0\x04\x08”: shellcode address inside “a” chunk
One thing to note here is the first 16 padding “A” bytes which are there because when free(a) gets called, some other data gets written to the memory locations where “a” chunk “User data” begins and that would overwrite our shellcode, so we just need to shift it by a few bytes (in this case 16) for it to not get overwritten.
Proof of work:

Image 8: proof that exploit code works
That’s it! Thanks for reading!
References
[1] Heap Overflows and Double-Free Attacks, http://homes.soic.indiana.edu/yh33/Teaching/I433-2016/lec13-HeapAttacks.pdf
[2] Heap overflow using unlink, https://sploitfun.wordpress.com/2015/02/26/heap-overflow-using-unlink/
[3] dlmalloc source code, ftp://g.oswego.edu/pub/misc/malloc.c




 4a008, at which is the content of the priority field (set to 1). Little before that is a field with 0x00000011. This field represents how many bytes does the allocation take and the last bit (PREV_INUSE flag bit is set, look at [1]) means that the previous chunk is allocated and because of that, the 0x00000000 bytes starting at address 0x804a000 represent user data (the same goes with the other chunks). We can also see that consecutive malloc calls gave consecutive accessible memory regions starting at: 0x804a008, 0x804a018, 0x804a028, 0x804a038.
4a008, at which is the content of the priority field (set to 1). Little before that is a field with 0x00000011. This field represents how many bytes does the allocation take and the last bit (PREV_INUSE flag bit is set, look at [1]) means that the previous chunk is allocated and because of that, the 0x00000000 bytes starting at address 0x804a000 represent user data (the same goes with the other chunks). We can also see that consecutive malloc calls gave consecutive accessible memory regions starting at: 0x804a008, 0x804a018, 0x804a028, 0x804a038.